ScreenAI คืออะไร? เอไอตัวใหม่ที่ Google ถึงปล่อยออกมาเมื่อวันที่ 19 มีนาคม 2024 มีความสามารถอะไร? ทำอะไรได้บ้าง? แล้วมันจะส่งผลกระทบกับวงการ AI และเรามากแค่ไหน?
เราได้เคยกล่าวถึง รวมบริการ Generative AI ประเภทต่าง ๆ ที่ใช้งานได้จริงในปัจจุบัน ไปแล้ว แต่ AI ยังพฒนาไม่หยุด การนำเอไอมาใช้กับ UI และ Infographic ก็เป็นอีกเรื่องหนึ่งที่นักวิจัยด้านเอไอให้ความสนใจ เพราะในทุกวันนี้ หน้าจอ UI และ Infographic เช่น แผนภูมิ ไดอะแกรม และตาราง มีบทบาทสำคัญในการสื่อสารทั้งระหว่างมนุษย์ด้วยกันเอง และมนุษย์กับเครื่องจักร เนื่องจากมีความสะดวก และสื่อสารได้หลากหลาย โดยทั้ง UI และอินโฟกราฟิกใช้หลักการการออกแบบและภาษาภาพที่คล้ายกัน (เช่น ไอคอนและเลย์เอาต์) ทำให้มีความเป็นไปได้ที่จะสร้างโมเดลเอไอที่เข้าใจทั้ง UI และ Infographic อย่างไรก็ตาม เนื่องจากความซับซ้อนและรูปแบบที่หลากหลายของ UI และ Infographic ทำให้มีความท้าทายในการสร้างโมเดลเอไออย่างมาก
ScreenAI คืออะไร?
ScreenAI เป็นโมเดลภาษาวิสัยทัศน์ (Vision-Language Model หรือ VLM) ที่เข้าใจทั้งภาพและข้อความที่อยู่บนหน้ายูสเซอร์อินเทอร์เฟซ (User Interface หรือ UI) และ Infographic พัฒนาโดยทีมงานวิจัยของ Google โมเดลเอไอ ScreenAI นี้พัฒนาต่อยอดมาจากสถาปัตยกรรม PaLI และงานวิจัย pix2struct
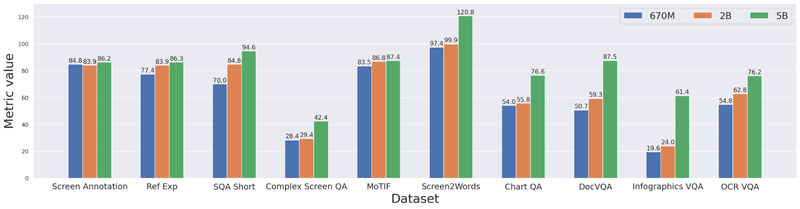
นอกจากนี้ ScreenAI ถูกฝึกด้วยชุดข้อมูลและงานที่หลากหลาย รวมถึงชุดข้อมูลแบบ Screen Annotation แบบใหม่ที่สามารถระบุองค์ประกอบของ UI (เช่น ประเภท ตำแหน่ง และคำอธิบาย) ได้ ข้อมูลเหล่านี้จะช่วยให้โมเดลภาษาขนาดใหญ่ (Large Language Models หรือ LLM) เข้าใจสิ่งที่อยู่บนหน้าจอ และสร้างชุดข้อมูลสำหรับการฝึกตอบคำถาม (QA) การระบุหน้า UI และการสรุปเนื้อหา ScreenAI ใช้พารามิเตอร์ 5 พันล้านตัว ซึ่งนับว่าใช้จำนวนพารามิเตอร์ไม่มากแต่กลับได้ผลลัพธ์ที่ดีเยี่ยม ScreenAI จึงเป็นก้าวสำคัญของงานวิจัยด้าน AI ที่มีความสามารถในการเข้าใจรูปภาพได้เหมือนมนุษย์
จุดเด่นของ ScreenAI คือ
- ScreenAI มีความยืดหยุ่น สามารถทำงานกับภาพที่มีสัดส่วนแตกต่างกันได้
- ScreenAI สามารถเข้าใจความสัมพันธ์เชิงพื้นที่ระหว่างองค์ประกอบต่างๆ บนหน้าจอ
- ScreenAI สามารถจำแนกประเภทไอคอนได้ถึง 77 ประเภท
- ScreenAI สามารถสร้างคำอธิบายภาพที่เป็นข้อความอธิบายรายละเอียด
- ScreenAI สามารถทำงานได้หลากหลายงานที่เกี่ยวข้องกับ UI และอินโฟกราฟิก
การทำงานของ ScreenAI
ScreenAI ประกอบด้วย 2 ส่วนหลักคือ
- ตัวเข้ารหัสหลายรูปแบบ (Multimodal Encoder) : ทำหน้าที่แยกแยะข้อมูลภาพ (Image) ผ่านเทคนิค Vision Transformer (ViT) และแปลงข้อความ (Text) ให้เป็นรูปแบบที่คอมพิวเตอร์เข้าใจ
- ตัวถอดรหัสอัตโนมัติถอยหลัง (Autoregressive Decoder) : ทำหน้าที่ถอดรหัสข้อมูลที่ผ่านการเข้ารหัสแล้ว ให้อยู่ในรูปแบบที่เราต้องการ
โดยสถาปัตยกรรม PaLI ที่เป็นพื้นฐานของ ScreenAI ถูกนำมาแก้ปัญหาให้ ScreenAI สามารถมองภาพเป็นแบบ ” text+image-to-text” ได้
นอกจากโครงสร้างพื้นฐาน PaLI แล้ว ScreenAI ยังใช้เทคนิคการแบ่งพื้นที่ภาพเป็นส่วนๆ ที่มีความยืดหยุ่นจากงานวิจัย pix2struct แทนการแบ่งภาพเป็นตารางสี่เหลี่ยมที่ตายตัว วิธีนี้จะทำให้สามารถปรับขนาดพื้นที่ให้พอดีกับสัดส่วนของภาพต้นฉบับได้ ทำให้ ScreenAI ทำงานได้ดีกับภาพหลาย ๆ สัดส่วน
การฝึกฝน ScreenAI แบ่งเป็น 2 ส่วนคือ
- การเรียนรู้ด้วยตัวเองเบื้องต้น (Pre-training) : ระบบจะสร้างข้อมูลคำอธิบายภาพ (Data labels) แบบอัตโนมัติ ข้อมูลเหล่านี้จะถูกนำไปฝึกฝนแบบ Vision Transformer (ViT) และโมเดลภาษา
- การปรับแต่งการเรียนรู้ (Fine-tuning) : ขั้นนี้ใช้ข้อมูลที่มนุษย์ระบุคำอธิบายไว้ป้อนเข้าระบบ โดยใช้การฝึกฝนแบบ Vision Transformer (ViT) เพื่อเน้นการเรียนรู้จากข้อมูลใหม่
ScreenAI ใช้โครงสร้างพื้นฐานที่มีความยืดหยุ่น ผสานกับเทคนิคการแบ่งพื้นที่รูปภาพ และการฝึกฝนแบบสองขั้นตอน ทำให้สามารถทำงานได้ดีกับภาพที่มีลักษณะหลากหลาย
การสร้างข้อมูลสำหรับฝึกฝน ScreenAI
กระบวนการสร้างชุดข้อมูลสำหรับฝึกฝน ScreenAI ประกอบด้วย 2 ส่วนหลัก:
1 รวบรวมภาพหน้าจอ (Screenshot) ซึ่งจะมีรายละเอียดดังนี้
- ทีมวิจัยรวบรวมภาพหน้าจอจากอุปกรณ์ต่างๆ ทั้งคอมพิวเตอร์ มือถือ และแท็บเล็ต
- วิธีการรวบรวมข้อมูลทำได้โดยใช้เว็บเพจสาธารณะ และเลียนแบบการสำรวจโปรแกรมมือถือแบบอัตโนมัติ ที่เคยใช้ในชุดข้อมูล RICO
2 การระบุและจัดหมวดหมู่ชิ้นส่วนบนหน้าจอ (Layout Annotation) ซึ่งจะมีรายละเอียดดังนี้
- ใช้โมเดล DETR ในการระบุและติดป้ายชิ้นส่วนต่างๆ บนหน้าจอ เช่น รูปภาพ ไอคอน ปุ่ม ข้อความ และความสัมพันธ์เชิงพื้นที่ของแต่ละส่วนเหล่านั้น
- สำหรับไอคอน จะมีการวิเคราะห์เพิ่มเติมด้วยระบบจำแนกประเภทไอคอน (Icon Classifier) ซึ่งสามารถแยกแยะไอคอนได้ถึง 77 แบบ
- การจำแนกประเภทอย่างละเอียดนี้จำเป็นสำหรับการแปลความหมายของข้อมูลที่ซ่อนอยู่ภายในไอคอน
- สำหรับไอคอน รูปภาพและอินโฟกราฟิก ที่ระบบจำแนกไม่ได้ ทีมวิจัยจะใช้โมเดล PaLI image captioning สร้างคำบรรยายภาพเพื่ออธิบายรายละเอียดและบริบทของภาพ
- นอกจากนี้ ยังมีการใช้ระบบ Optical Character Recognition (OCR) เพื่อดึงข้อความบนหน้าจอมาแปลเป็นตัวอักษรและจัดหมวดหมู่ ข้อความเหล่านี้จะถูกนำไปรวมกับข้อมูลที่ระบุไปก่อนหน้านี้ เพื่อสร้างคำอธิบายรายละเอียดของแต่ละหน้าจอ
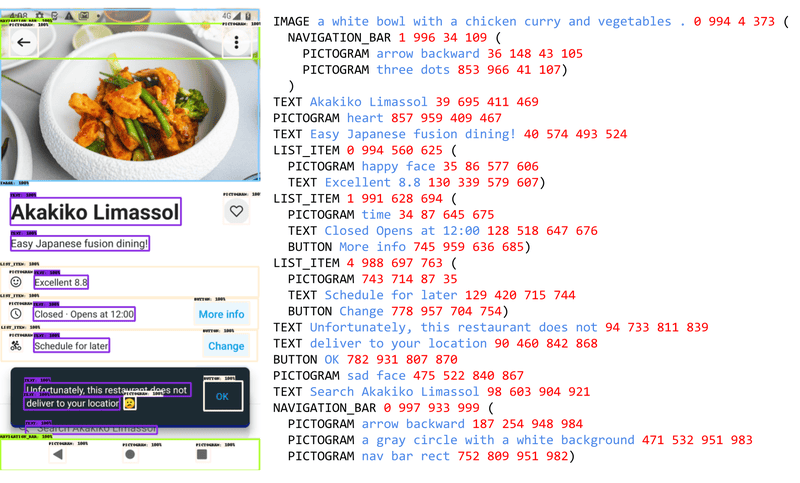
การสร้างข้อมูลหลากหลายด้วย Large Language Models หรือ LLM
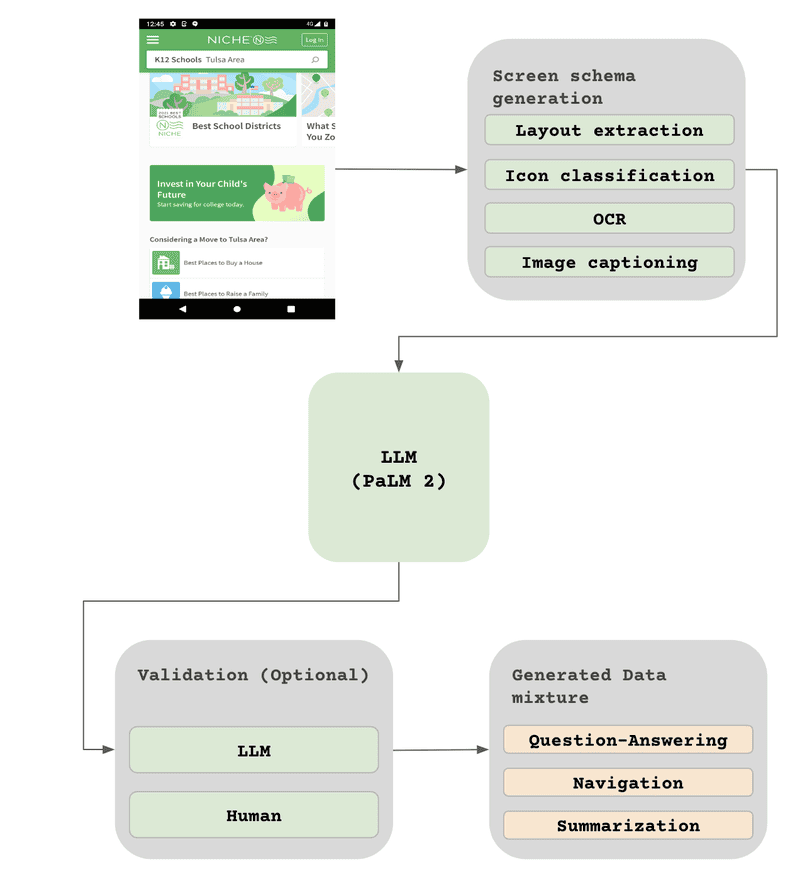
นอกจากการรวบรวมข้อมูลหน้าจอของจริงแล้ว ทีมวิจัยยังใช้เอไอ PaLM 2 เพื่อสร้างข้อมูลหลากหลายขึ้น กระบวนการนี้แบ่งเป็น 2 ขั้นตอน
- สร้างคำอธิบายหน้าจอเบื้องต้น : ใช้เทคนิคเดียวกับการสร้างข้อมูลจริงตามที่กล่าวไปข้างต้น
- สร้างข้อมูลเทียมด้วย PaLM 2 : ใช้คำอธิบายหน้าจอเบื้องต้นเป็นโครงสร้างหลัก จากนั้นออกแบบคำสั่ง (prompt) เพื่อสั่ง PaLM 2 ให้สร้างข้อมูลเทียมขึ้นมา เช่น “สร้างภาพหน้าจอที่มีปุ่ม ‘ยืนยัน’ สีเขียว อยู่ด้านล่างขวาของรูปภาพสินค้า” ซึ่งการออกแบบคำสั่ง (prompt engineering) เป็นขั้นตอนสำคัญ ที่ต้องใช้ความละเอียดรอบคอบ และผ่านการตรวจสอบโดยมนุษย์ เพื่อให้แน่ใจว่าตรงตามเกณฑ์ที่ตั้งไว้
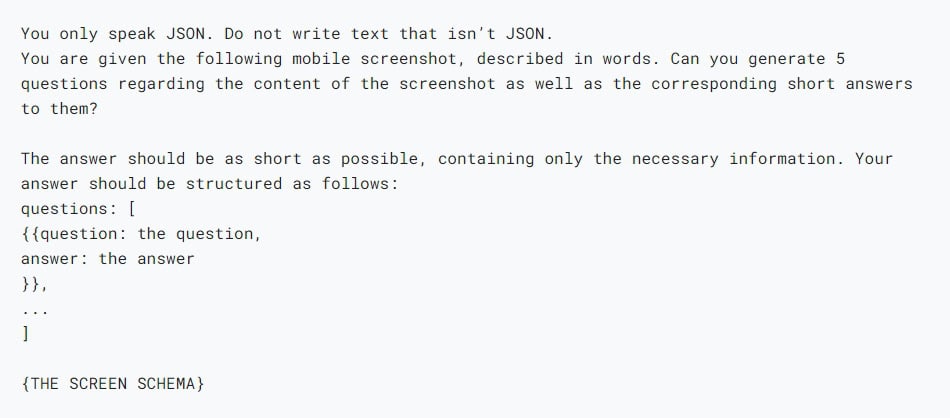
ด้วยการผสมผสานความสามารถด้านภาษาธรรมชาติของ LLM เข้ากับโครงสร้างข้อมูลที่เป็นระเบียบ ทำให้ทีมวิจัยสามารถจำลองการโต้ตอบของผู้ใช้ในสถานการณ์ต่างๆ ได้หลากหลาย เพื่อสร้างโจทย์เทียมที่สมจริง โดยโจทย์เหล่านี้แบ่งออกเป็น 3 ประเภทคือ
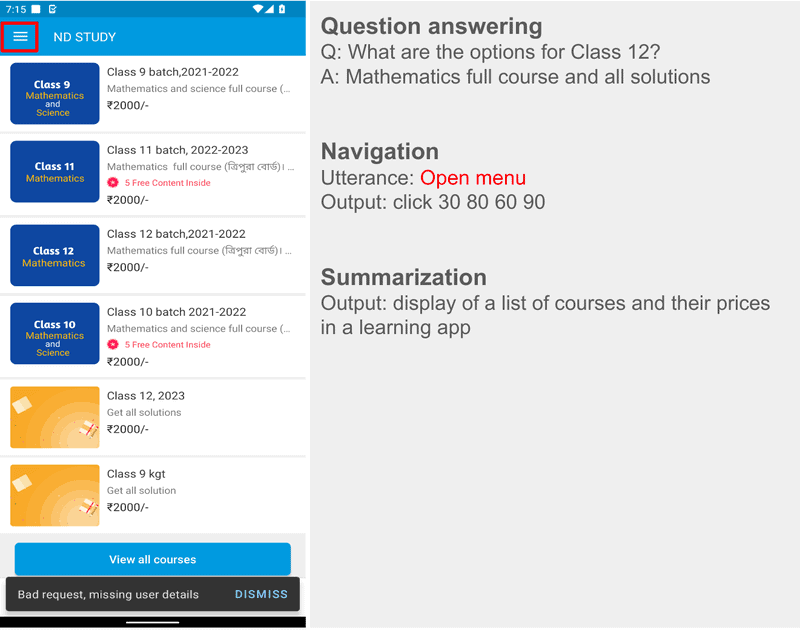
- ตอบคำถาม (Question answering) : ระบบจะถูกถามคำถามเกี่ยวกับเนื้อหาในภาพหน้าจอ เช่น “ร้านอาหารเปิดกี่โมง”
- ควบคุมหน้าจอ (Screen navigation) : ระบบจะได้รับคำสั่งเป็นภาษาธรรมชาติ ให้ทำการกระทำบางอย่างบนหน้าจอ เช่น “คลิกที่ปุ่มค้นหา”
- สรุปหน้าจอ (Screen summarization) : ระบบจะสรุปเนื้อหาบนหน้าจอด้วยประโยคสั้นๆ หนึ่งหรือสองประโยค
การฝึกฝน ScreenAI
อย่างที่กล่าวไปข้างต้น ScreenAI ถูกฝึกฝนด้วย 2 ส่วน การฝึกฝนเบื้องต้น (Pre-training) และการปรับแต่งการเรียนรู้ (Fine-tuning) โดยในขั้นตอนนี้ จะใช้ชุดข้อมูลสาธารณะสำหรับการตอบคำถาม (QA) การสรุปเนื้อหา และการควบคุมหน้าจอ รวมถึงงานต่างๆ ที่เกี่ยวข้องกับ UI ซึ่งมีรายละเอียดดังนี้
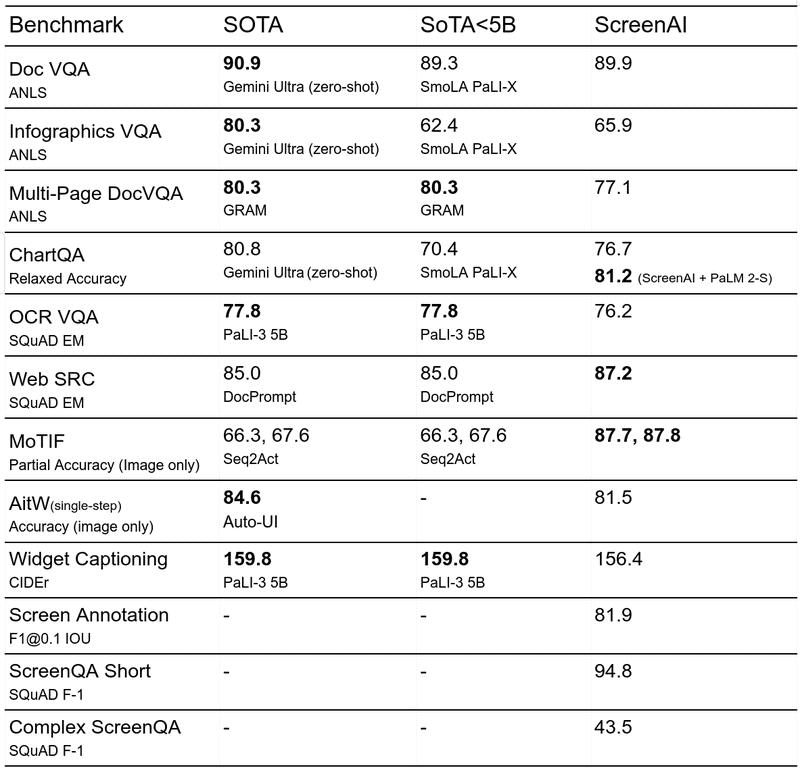
- การตอบคำถาม (QA) : ใช้ชุดข้อมูลมาตรฐานด้านการทำความเข้าใจเอกสารและข้อมูลหลายรูปแบบ เช่น ChartQA, DocVQA, Multipage DocVQA, InfographicVQA, OCR VQA, Web SRC และ ScreenQA
- การควบคุมหน้าจอ (Navigation) : ใช้ชุดข้อมูล ได้แก่ Referring Expressions, MoTIF, Mug และ Android in the Wild
- การสรุปหน้าจอ (Summarization) : ใช้ชุดข้อมูล Screen2Words
นอกจากชุดข้อมูลสำหรับปรับแต่งการเรียนรู้แล้ว ทีมวิจัยยังประเมินประสิทธิภาพของโมเดล ScreenAI ที่ผ่านการปรับแต่งด้วยเกณฑ์ประเมินใหม่ 3 แบบ:
- Screen Annotation : ช่วยประเมินความสามารถในการระบุโครงสร้างหน้าจอและความเข้าใจเชิงพื้นที่ของโมเดล
- ScreenQA Short : เป็นรูปแบบย่อของ ScreenQA โดยคำตอบที่ถูกต้องจะถูกตัดให้เหลือเฉพาะข้อมูลที่เกี่ยวข้อง เพื่อให้สอดคล้องกับงานตอบคำถามอื่นๆ
- Complex ScreenQA : การทดสอบที่ยากขึ้นกว่า ScreenQA Short (เช่น การนับ การคำนวณ การเปรียบเทียบ และคำถามที่ไม่มีคำตอบ) และมีหน้าจอที่สัดส่วนภาพแตกต่างกัน
ผลลัพธ์ที่ได้คือ ScreenAI ที่ผ่านการปรับแต่ง และมีประสิทธิภาพที่ยอดเยี่ยมในงานต่างๆ ที่เกี่ยวข้องกับ UI และอินโฟกราฟิก และมีประสิทธิภาพดีที่สุดเมื่อเปรียบเทียบกับโมเดลเอไอที่มีขนาดใกล้เคียงกัน นอกจากนี้ ScreenAI ยังทำงานได้อย่างมีประสิทธิภาพในระดับที่แข่งขันได้กับโมเดลเอไอตัวอื่น ๆ ได้อีกด้วย
สรุป ScreenAI คืออะไร?
ScreenAI คือโมเดล AI เป็นโมเดลภาษาวิสัยทัศน์ (Vision-Language Model หรือ VLM) ที่เข้าใจทั้งภาพและข้อความสำหรับหน้ายูสเซอร์อินเทอร์เฟซ (User Interface หรือ UI) และ Infographic มีความสามารถหลากหลาย เช่น ตอบคำถามเกี่ยวกับเนื้อหาในภาพ ควบคุมหน้าจอ สรุปเนื้อหาหน้าจอ และถึงมันจะมีความสามารถที่หลากหลาย แต่ก็ยังอยู่ในขั้นของการพัฒนาเท่านั้น ScreenAI จะถูกปล่อยออกมาให้เราใช้กันได้เมื่อไหร่ ก็ต้องติดตามกันต่อไป
อ้างอิง Google Research cover iT24Hrs
อ่านบทความและข่าวอื่นๆเพิ่มเติมได้ที่ it24hrs.com
ScreenAI คืออะไร? เอไอที่เข้าใจภาพและข้อความของ UI และ Infographic
อย่าลืมกดติดตามอัพเดตข่าวสาร ทิปเทคนิคดีๆกันนะคะ Please follow us
Youtube it24hrs
Twitter it24hrs
Tiktok it24hrs
facebook it24hrs




